|
Dongyang Fan Hi! Thanks for stopping by :) I'm a passionate 4th-year PhD student at Machine Learning and Optimization Lab at EPFL, supervised by Prof. Martin Jaggi. My name is pronounced as Don-Young. My research interests include:
Email / Google Scholar / Semantic Scholar / Twitter / Github / LinkedIn |

|
Research
|
|
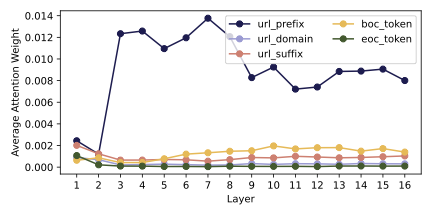
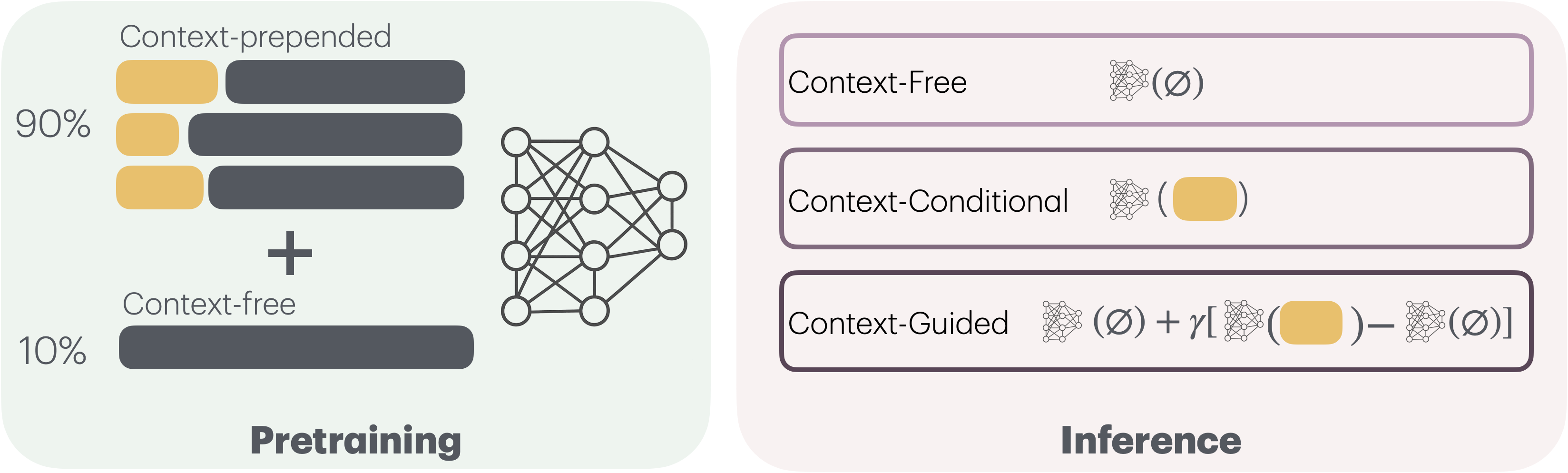
Beyond URLs: Metadata Diversity and Position for Efficient LLM Pretraining
Dongyang Fan*, Diba Hashemi*, Sai Praneeth Karimireddy, Martin Jaggi preprint, 2025 arXiv |

|
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Apertus team (as a member of the pretraining team) preprint, 2025 arXiv |
|
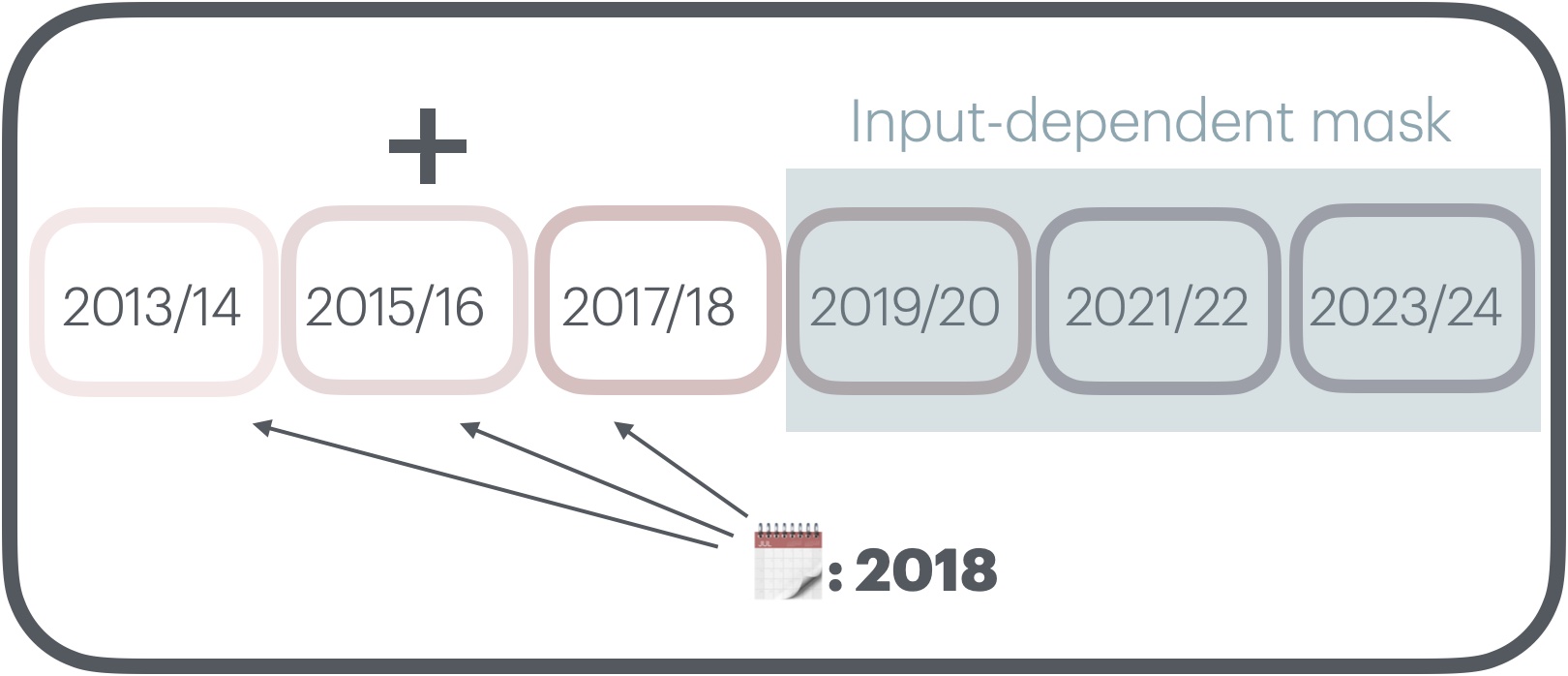
TiMoE: Time-Aware Mixture of Language Experts
Robin Faro*, Dongyang Fan*, Tamar Alphaidze, Martin Jaggi XTempLLMs workshop @ COLM (oral 🏆), 2025 arXiv / codes / slides |
|
URLs Help, Topics Guide: Understanding Metadata Utility in LLM Training
Dongyang Fan, Vinko Sabolčec, Martin Jaggi, Conference on Neural Information Processing Systems (NeurIPS), 2025 arXiv |
|
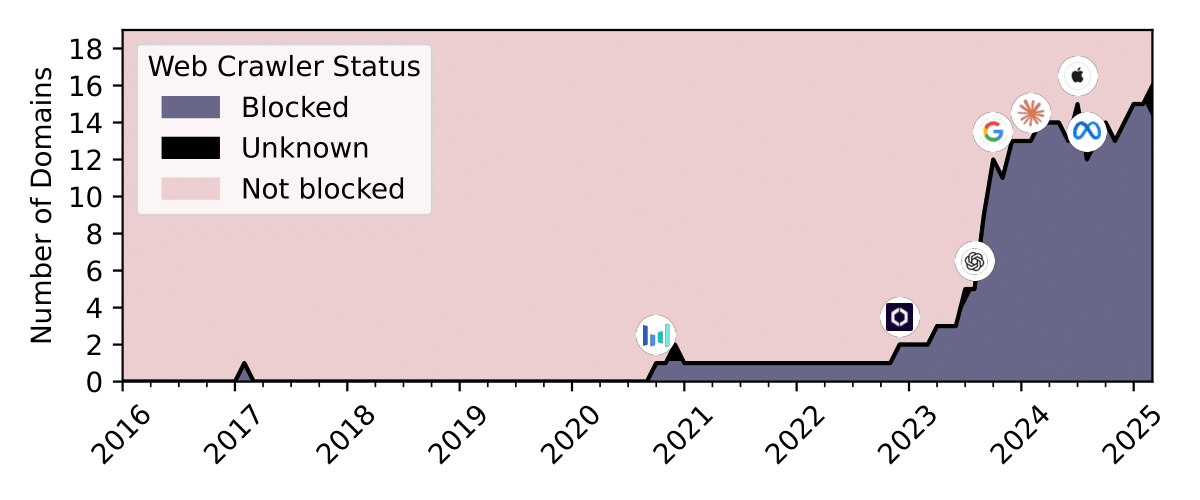
Can Performant LLMs Be Ethical? Quantifying the Impact of Web Crawling Opt-Outs
Dongyang Fan, Vinko Sabolčec, Matin Ansaripour, Ayush Kumar Tarun, Martin Jaggi, Antoine Bosselut, Imanol Schlag Conference on Language Modeling (COLM, oral 🏆), 2025 arXiv / codes / project page / slides |
|
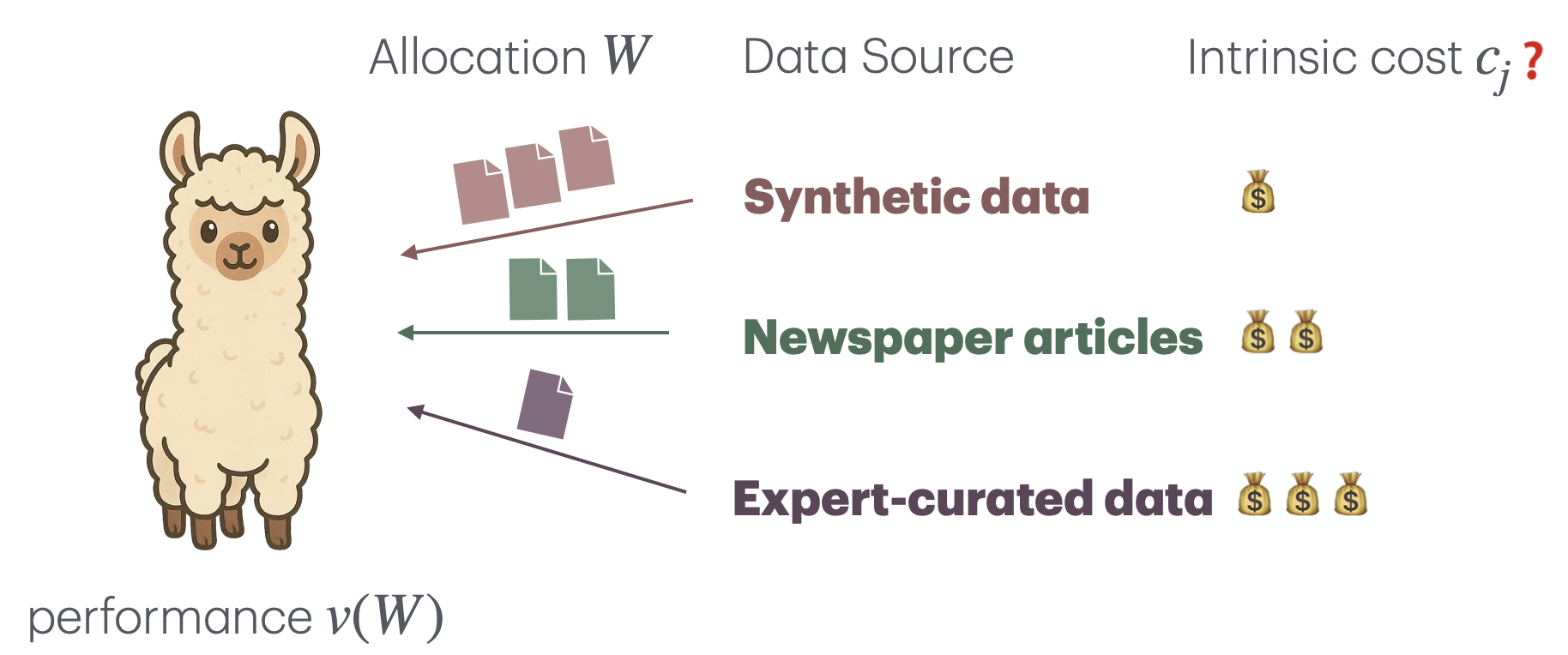
Do Data Valuations Make Good Data Prices?
Dongyang Fan, Tyler J. Rotello, Sai Praneeth Karimireddy ICLR Workshop Data Problems, 2025 arXiv |
|
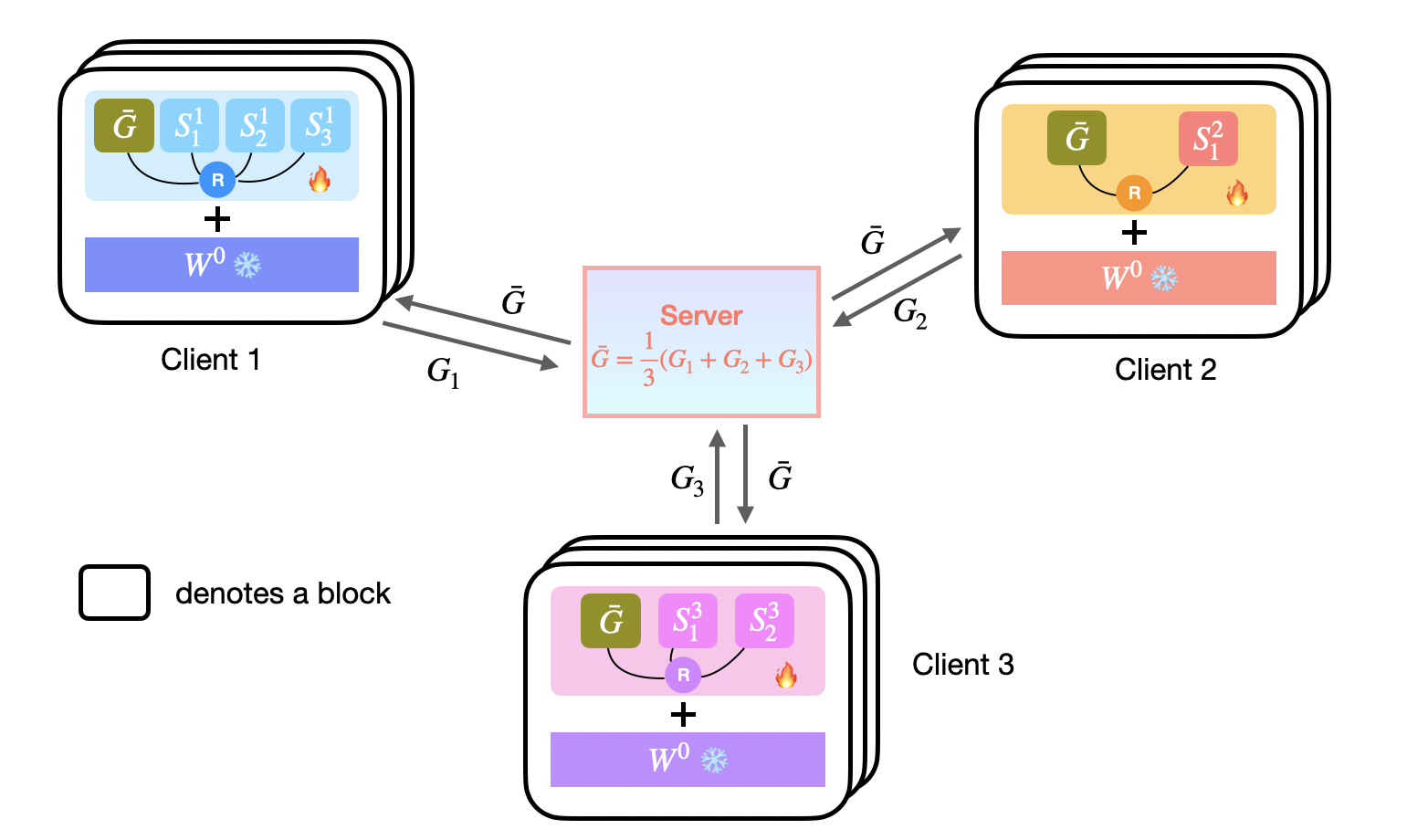
On-Device Collaborative Language Modeling via a Mixture of Generalists and Specialists
Dongyang Fan*, Bettina Messmer*, Nikita Doikov, Martin Jaggi International Conference on Machine Learning (ICML), 2025 codes / arXiv |
|
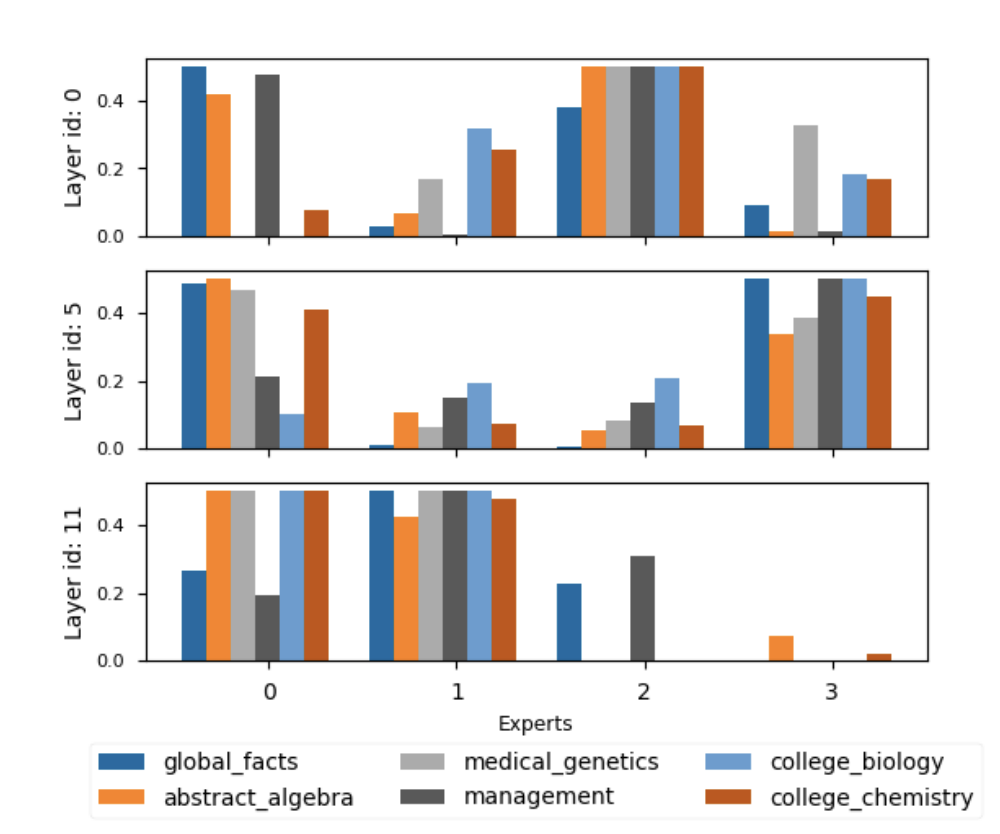
Towards an empirical understanding of MoE design choices
Dongyang Fan*, Bettina Messmer*, Martin Jaggi ICLR ME-FoMo Workshop, 2024 arXiv |
|
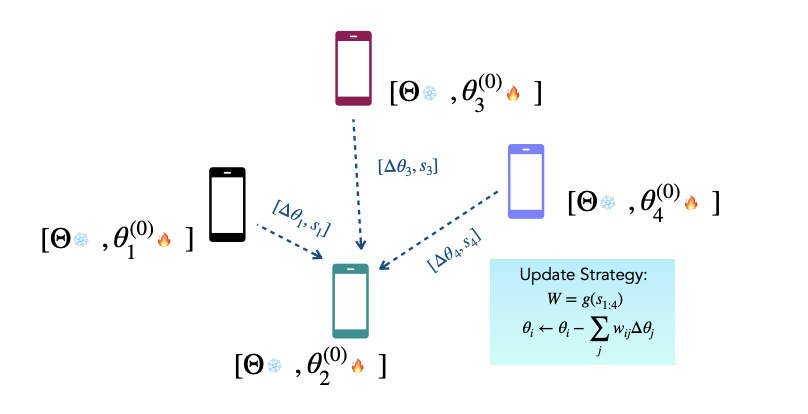
Personalized Collaborative Fine-Tuning for On-Device Large Language Models
Nicolas Wagner, Dongyang Fan, Martin Jaggi Conference on Language Modeling (COLM), 2024 codes / arXiv |

|
Ghost Noise for Regularizing Deep Neural Networks
Atli Kosson, Dongyang Fan, Martin Jaggi Association for the Advancement of Artificial Intelligence (AAAI), 2024 arXiv |
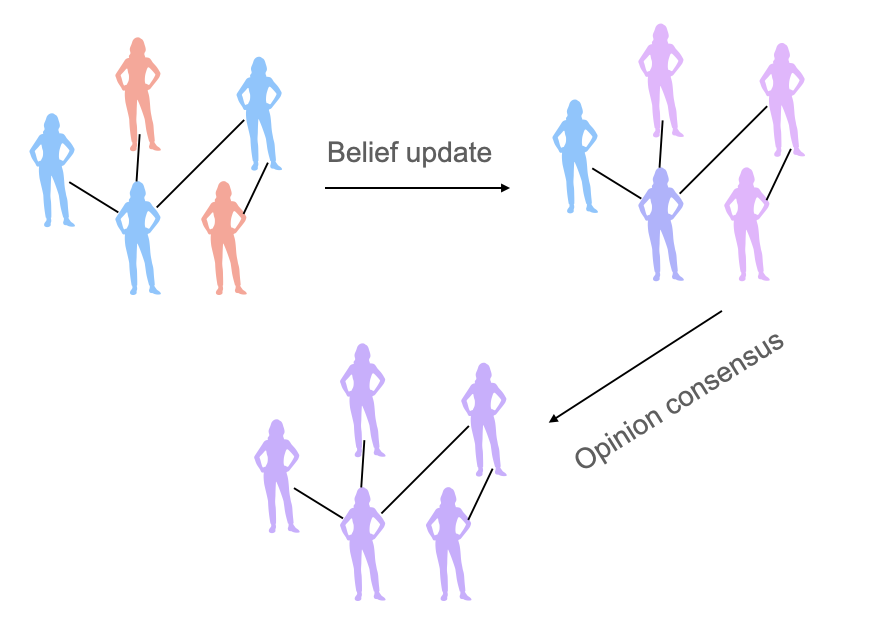
|
Collaborative Learning via Prediction Consensus
Dongyang Fan, Celestine Mendler-Dünner, Martin Jaggi Conference on Neural Information Processing Systems (NeurIPS), 2023 codes / arXiv / poster |
Academic Service
|
MiscellaneousIn general I like arts and cultural stuff. I am also an outdoorsy person and I do hiking skiing and sailing. I paint from my hiking trips. For example... 

|
|
Source codes of the website are from here. |